数组:数组是最最基本的数据结构,很多语言都内置支持数组。数组是使用一块连续的内存空间保存数据,保存的数据的个数在分配内存的时候就是确定的。(如图所示)

链表:存储的数据在地址空间上可连续,可不连续,链表中的每一个节点都包括数据和指向下一个地址的指针,查找数据的时间复杂度为O(n),方便数据的增删。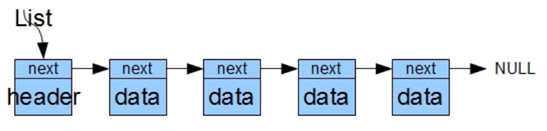
栈:栈是一种先入后出的逻辑结构,每次加入新的元素和拿走元素都在顶部操作。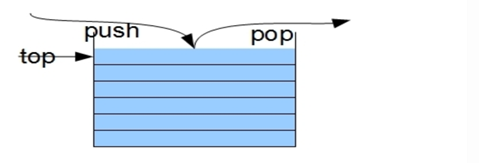
对列:是一种先入后出的逻辑结构,对于元素的操作分别在队头和队尾,元素的插入在队尾,元素的删除在队头。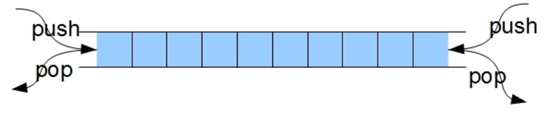
二叉树:每个节点至多只有两个子树的结构,在父节点中有指向左右子树的指针。
二叉树的 先序遍历:根–左–右。中序遍历:左–根–右。后序遍历:左–右–根。
查找二叉树:左子树的值小于根节点的值,右子树的值大于根节点的值,在插入数据时,从根节点开始往下比较,小于比较值则放在左边,大于比较值放在右边。插入一个值的时间复杂度是O(logn)。
平衡二叉树:左右子树的高度差的绝对值不超过1。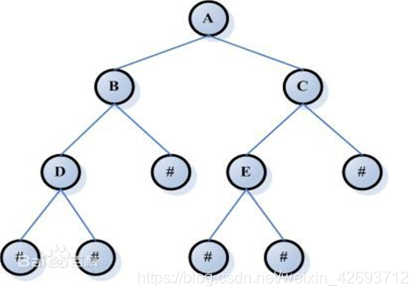
8种排序算法,原理,以及适用的场景和复杂度
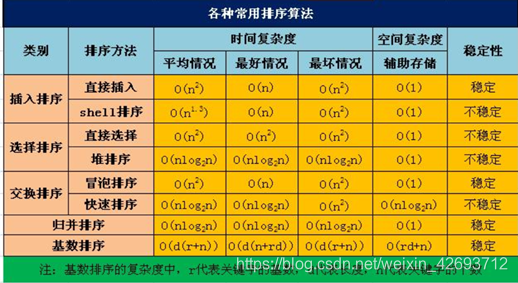
这里就体现2个常问的问题:冒泡排序的原理:
S1:从待排序序列的起始位置开始,从前往后依次比较各个位置和其后一位置的大小并执行S2。
S2:如果当前位置的值大于其后一位置的值,就把他俩的值交换(完成一次全序列比较后,序列最后位置的值即此序列最大值,所以其不需要再参与冒泡)。
S3:将序列的最后位置从待排序序列中移除。若移除后的待排序序列不为空则继续执行S1,否则冒泡结束。
在举个栗子
快速排序:快速排序是对冒泡排序的一种改进。基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此实现整个数据变成有序序列
在举个栗子:
费波拉切数列的实现方法
