所需jar包 链接:https://pan.baidu.com/s/1dV0cocLamZlm5NC89ZjEmQ
提取码:dasa
基于windows开发hadoop应用程序
1. 搭建hdfs环境
1.1 解压hadoop.tar.gz到一个目录下
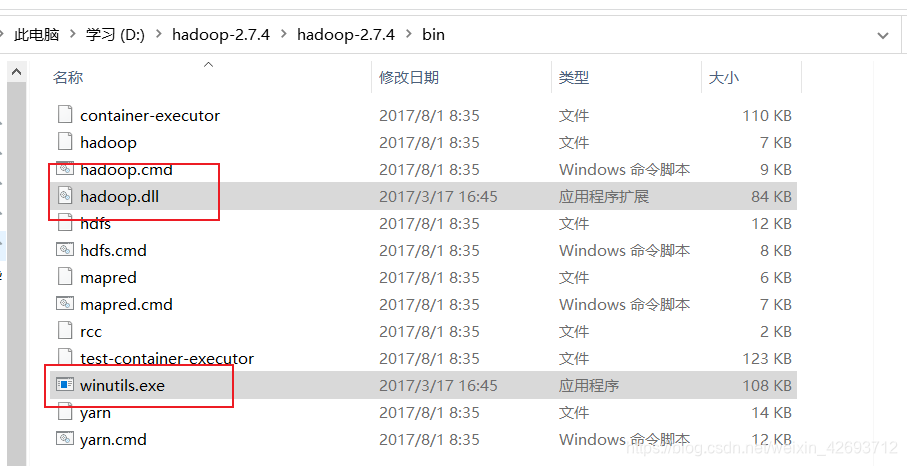
1.2 配置环境变量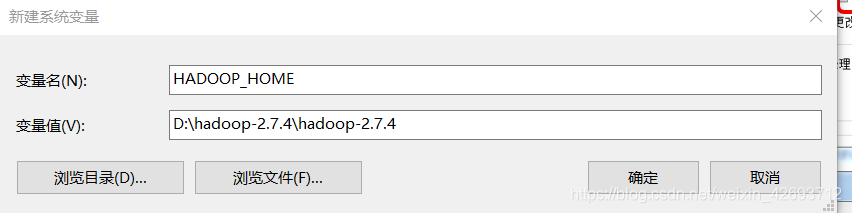
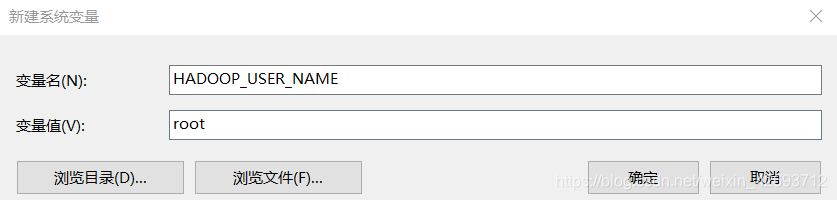
1.3 path里面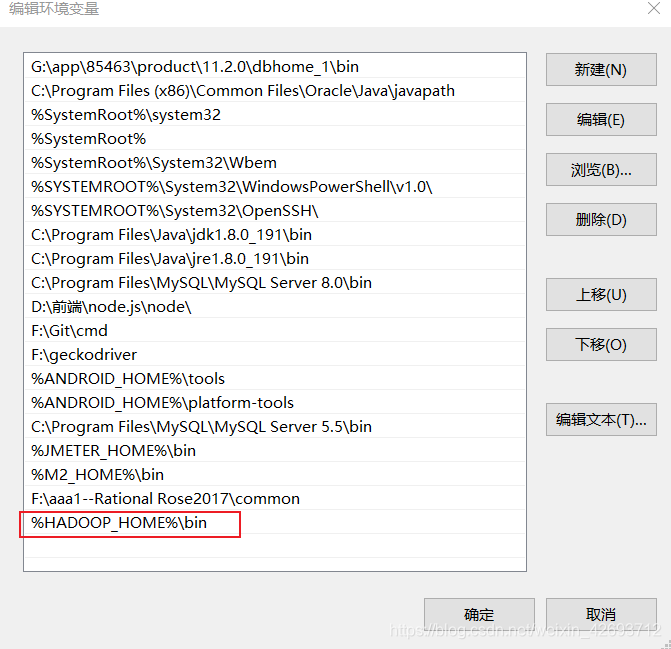
1.4 打开eclipse的plugins目录
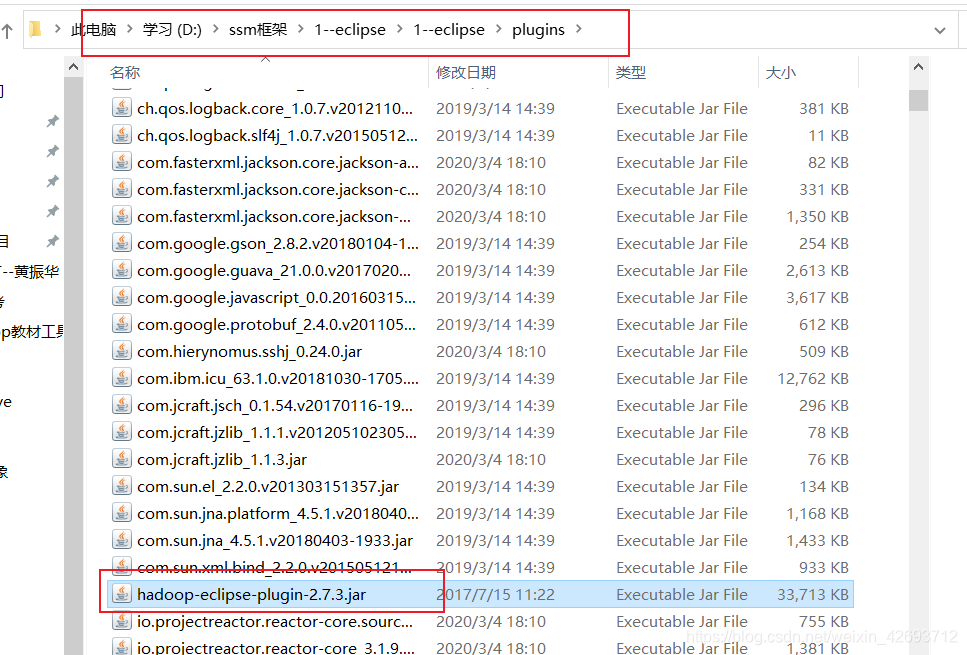
1.5 导入后重新启动eclipse
按下图操作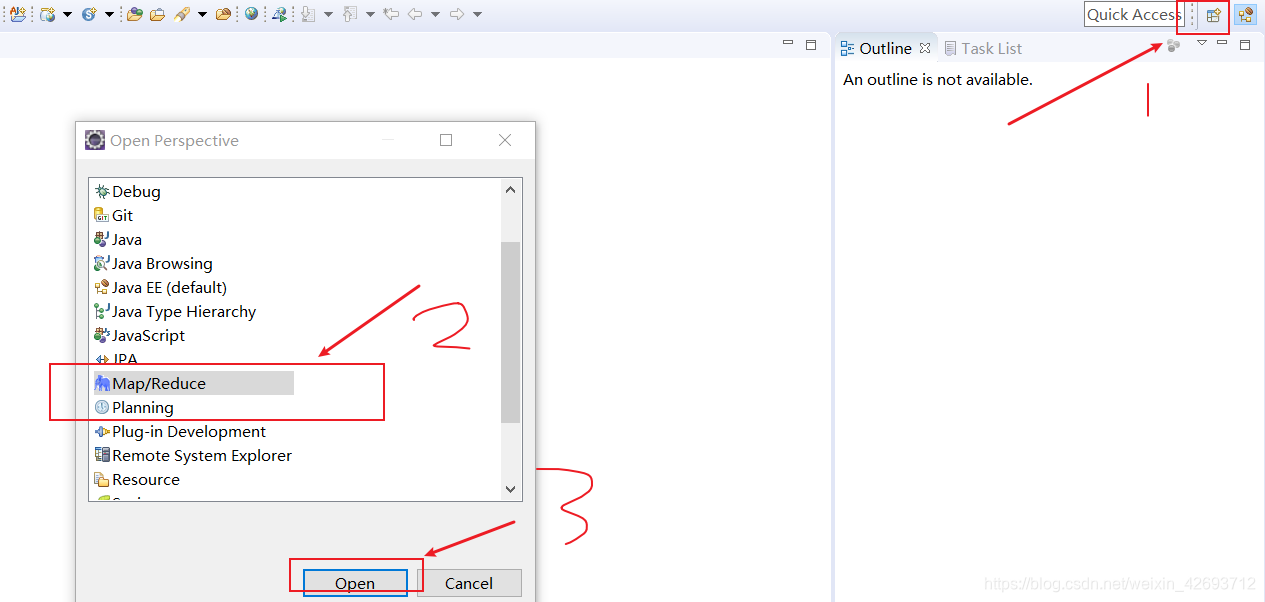
切换到map/reduce,点击小象
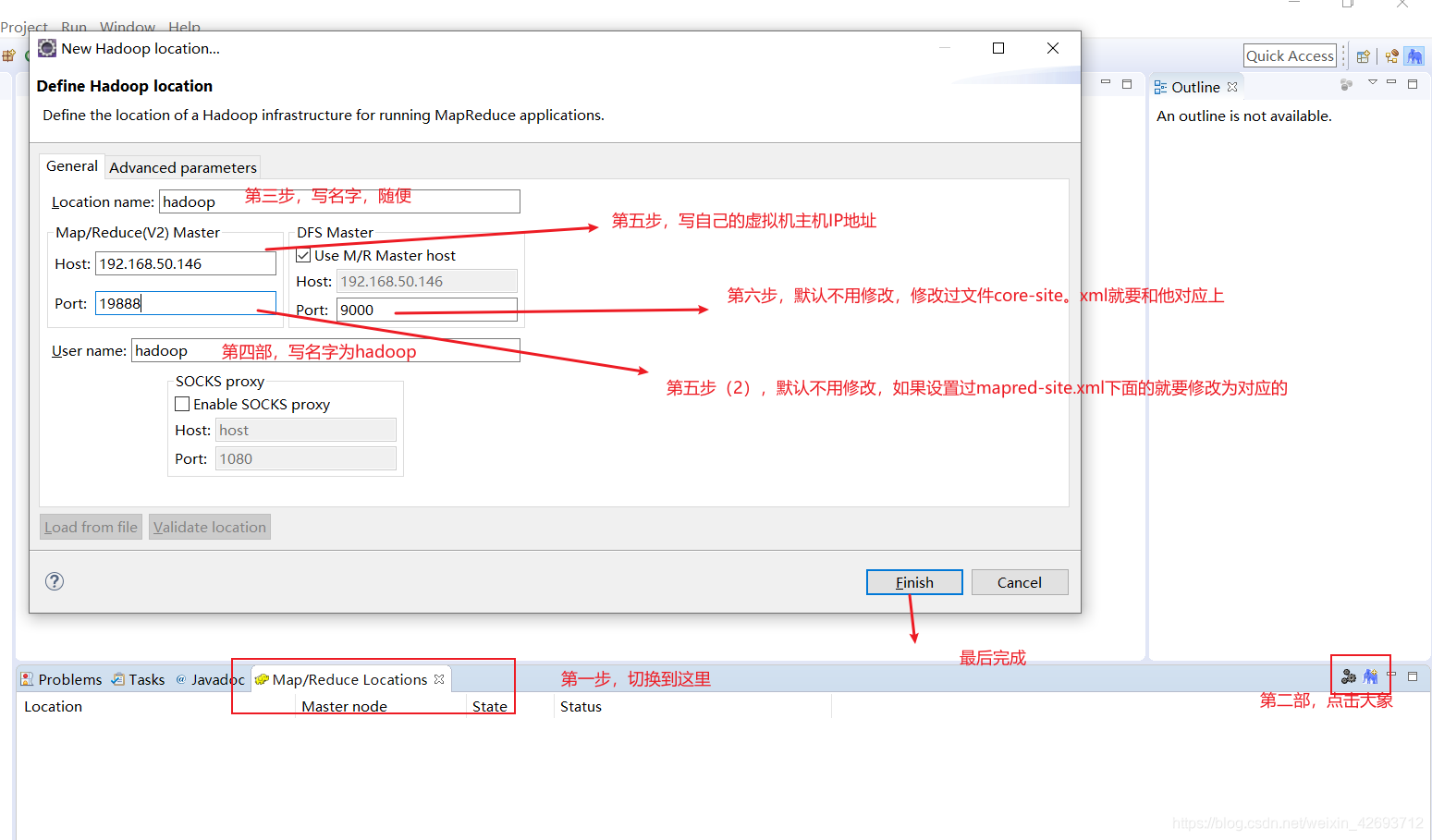
vi mapred-site.xml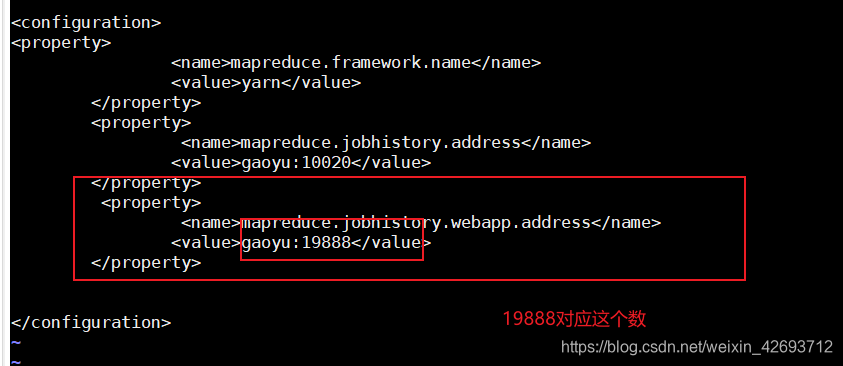
vi core-site.xml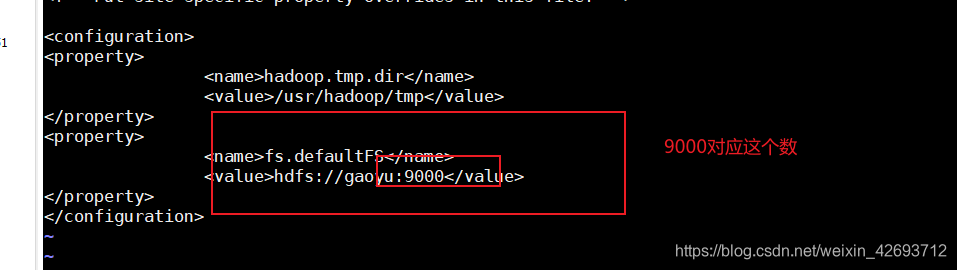
配置完如果还报错不用管,忽略即可
类似于这样的错误
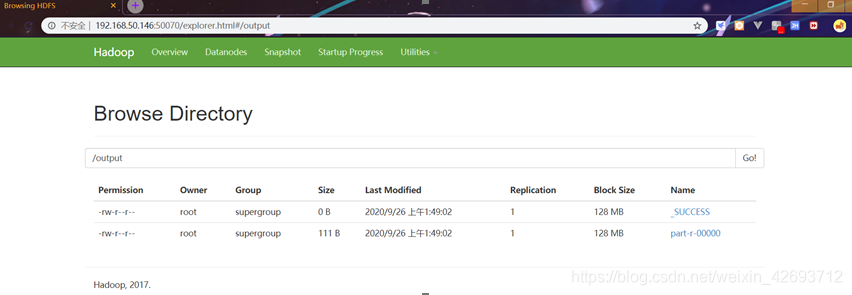
1.6 输入网址(http://192.168.50.146:50070/explorer.html#/)查看已经显示文件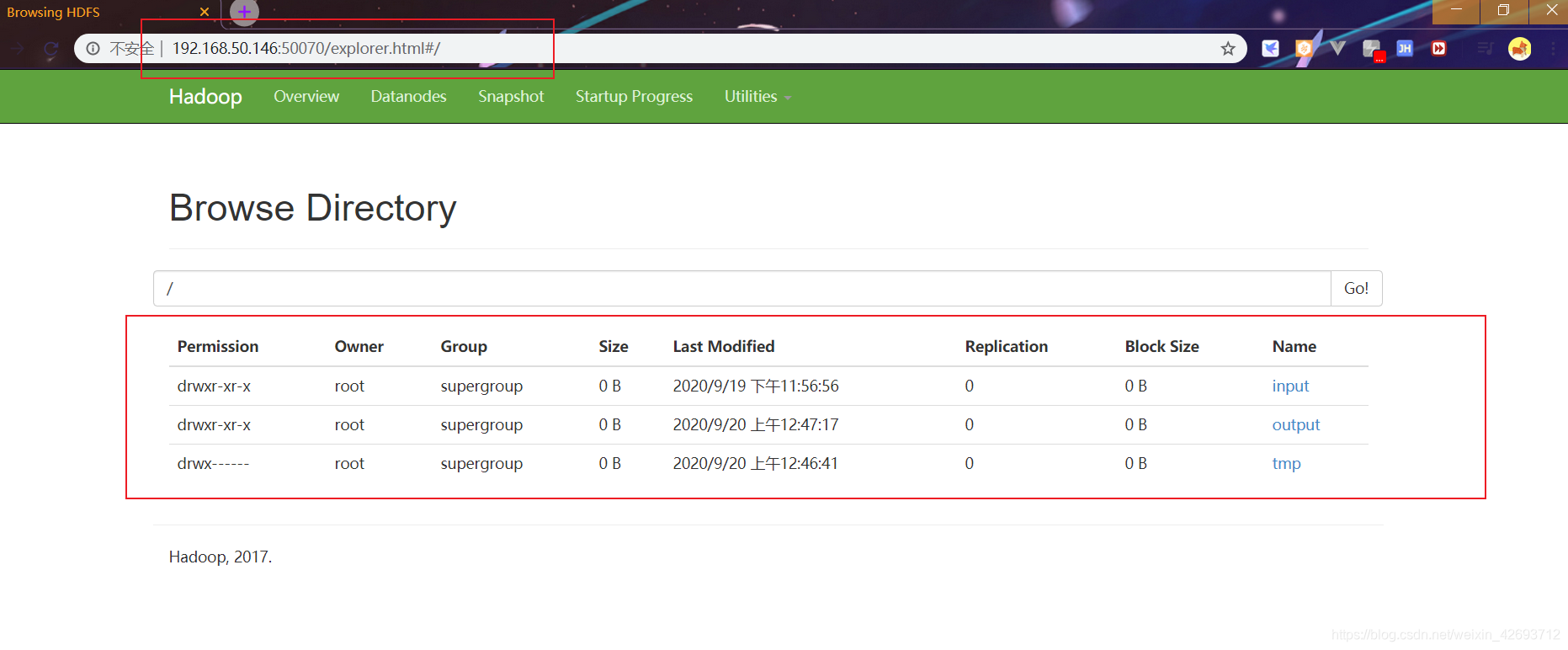
配置完成查看eclipse里面的树已经显示(第一次不显示,需要新建项目后显示,所以不显示也不要着急)
这是显示的树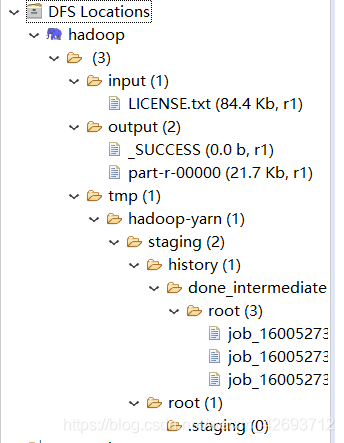
2.基于windows开发hadoop应用程序
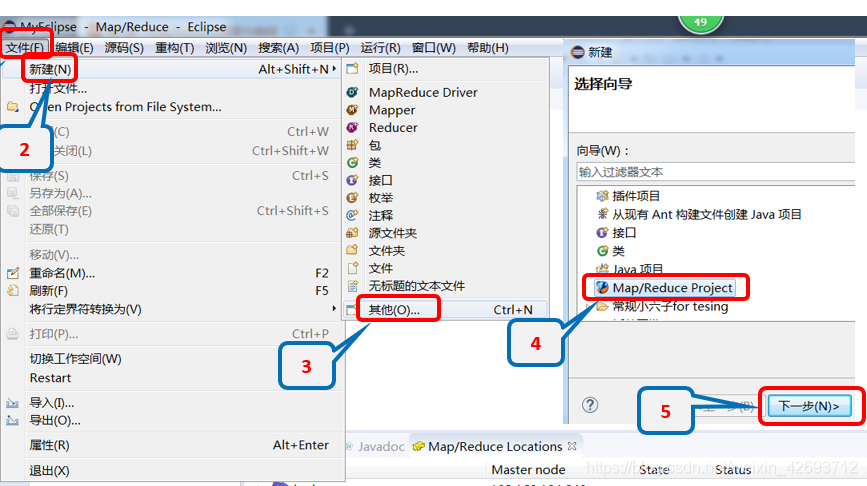
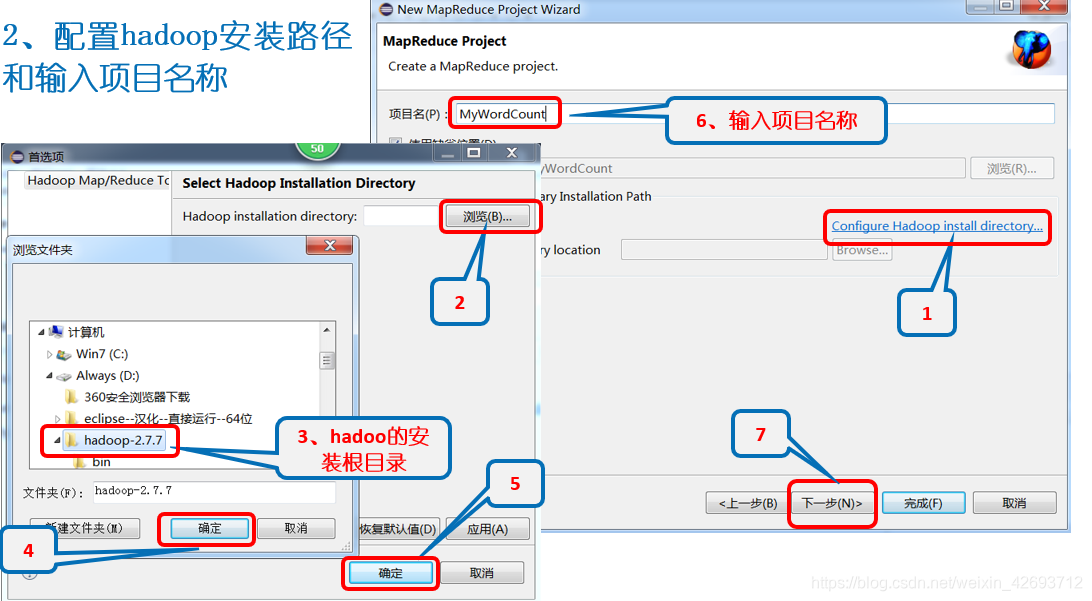
2.1 添加外部扩展jar包,在自己的linux下(这3个jar包)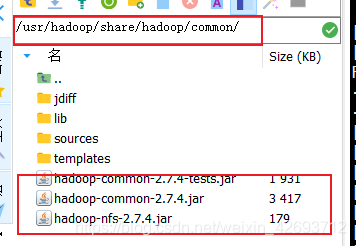
可以先复制到自己的机器上在添加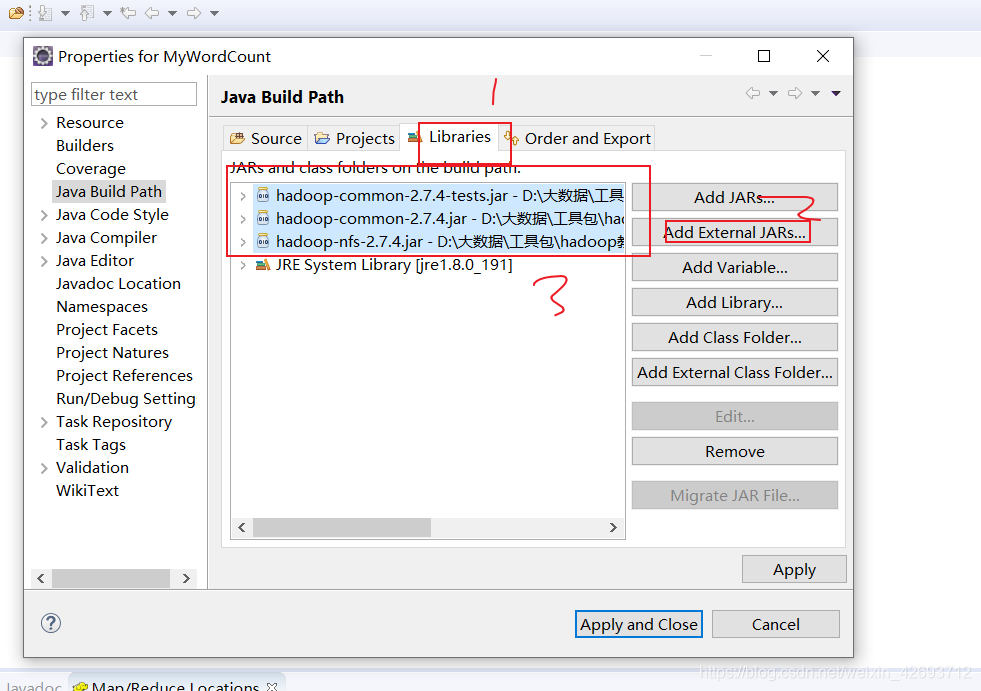
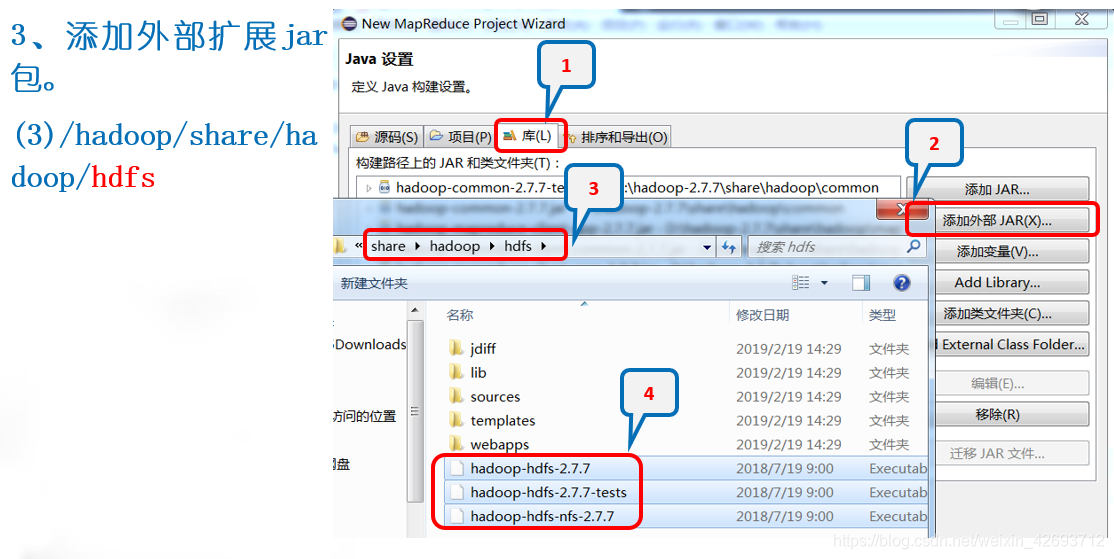
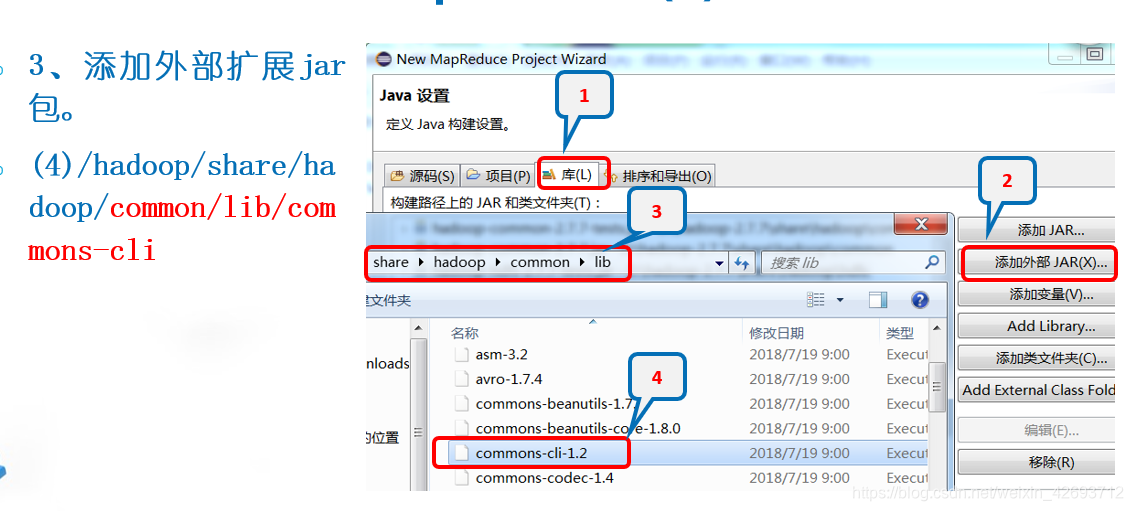
同理添加以下jar包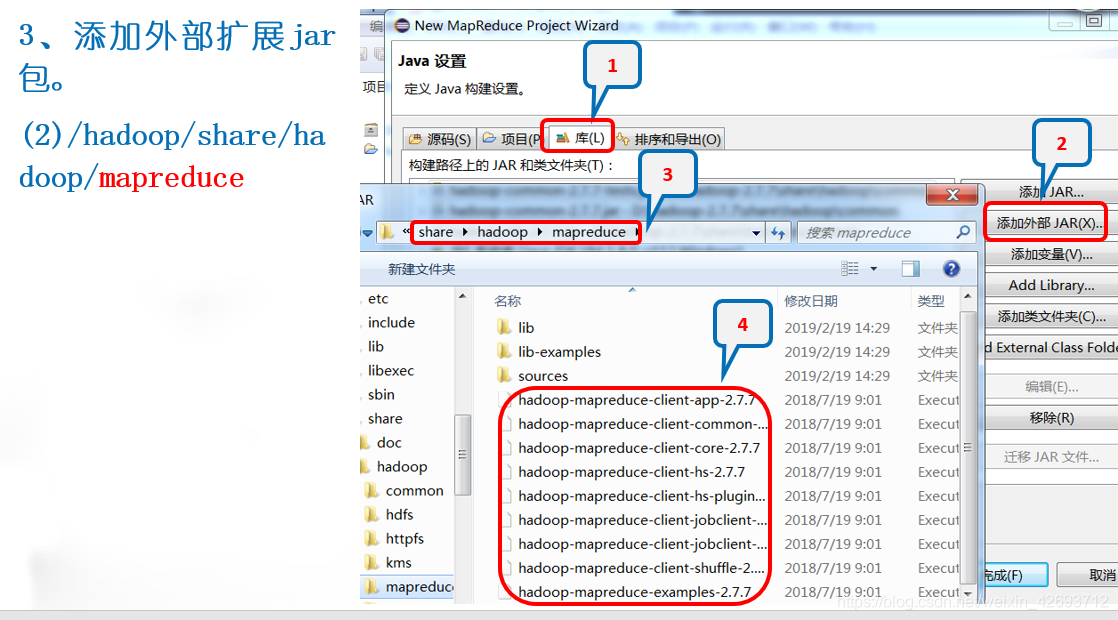
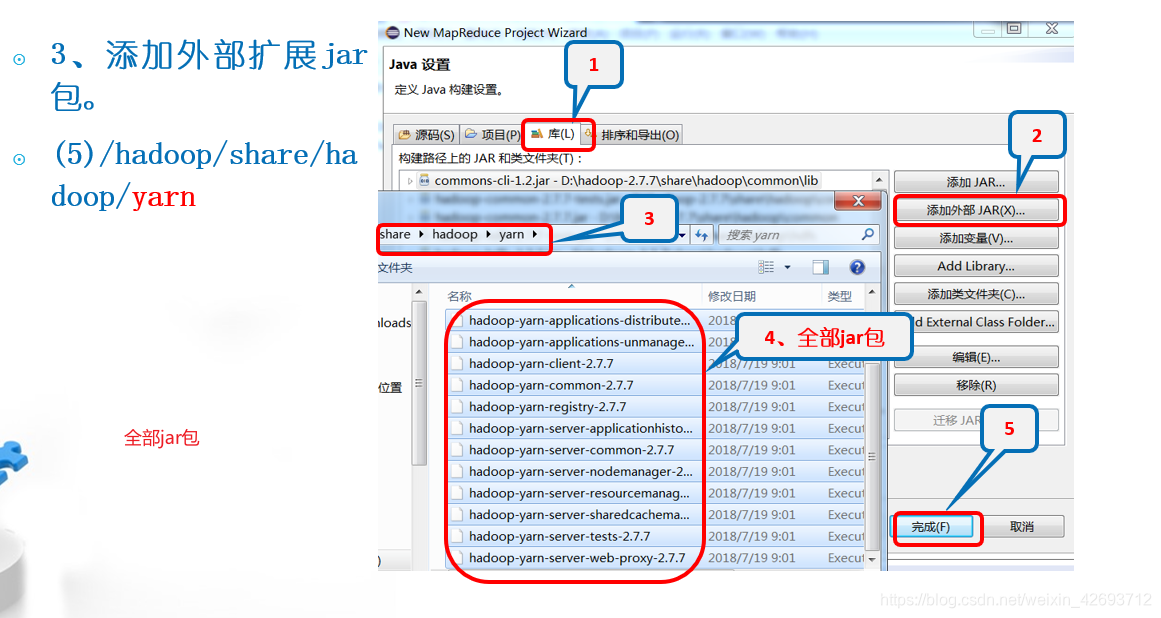
导入成功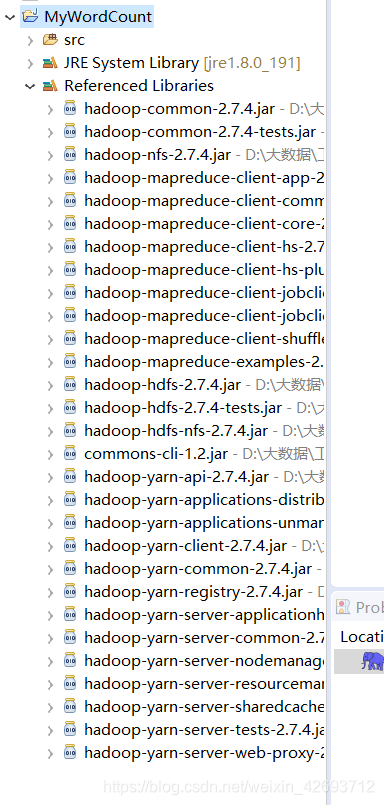
2.2 右键项目新建class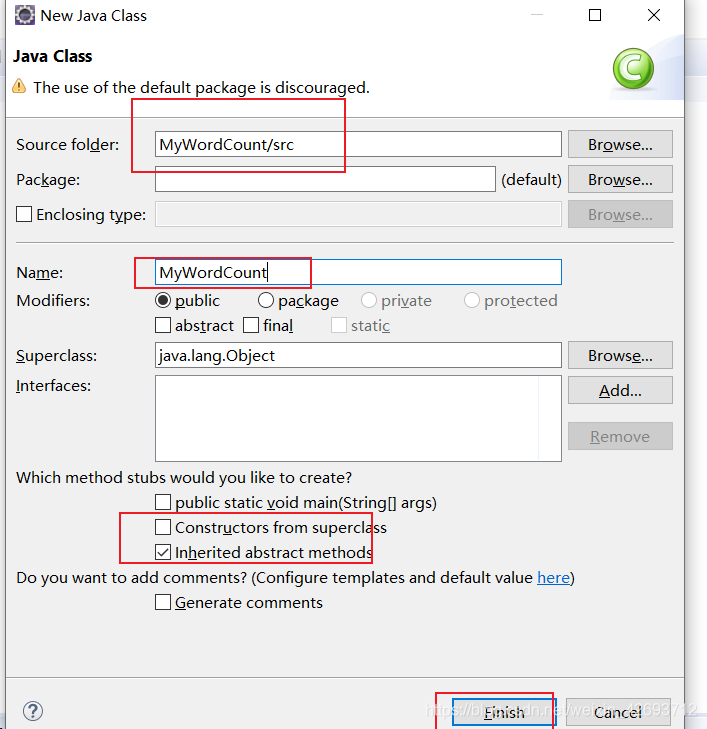
类里面的内容
1 | import java.io.IOException; |
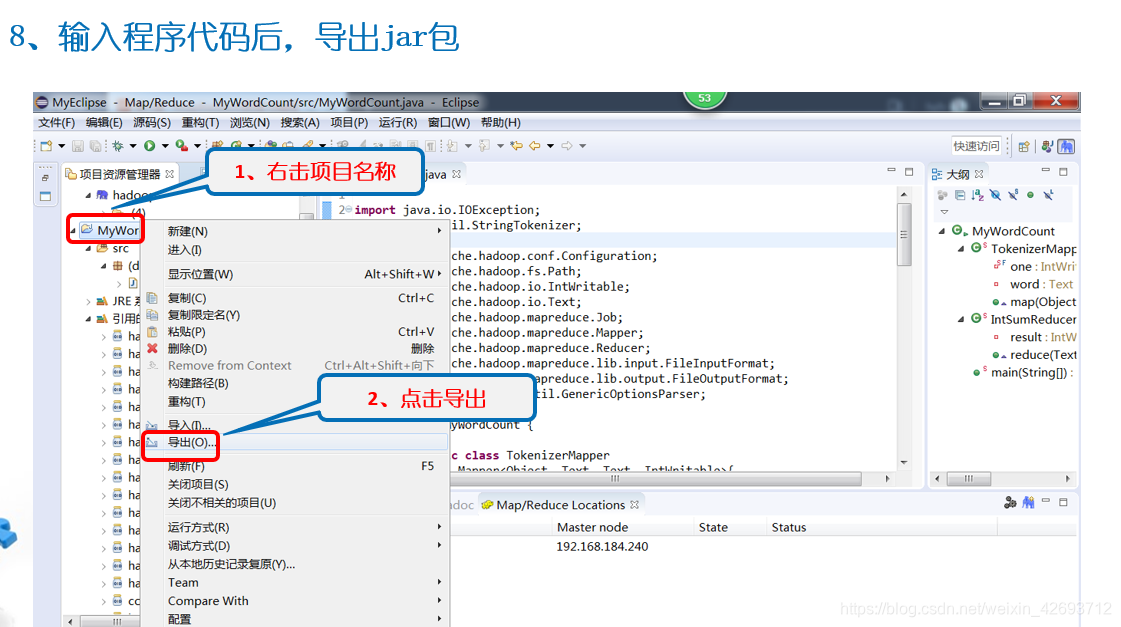
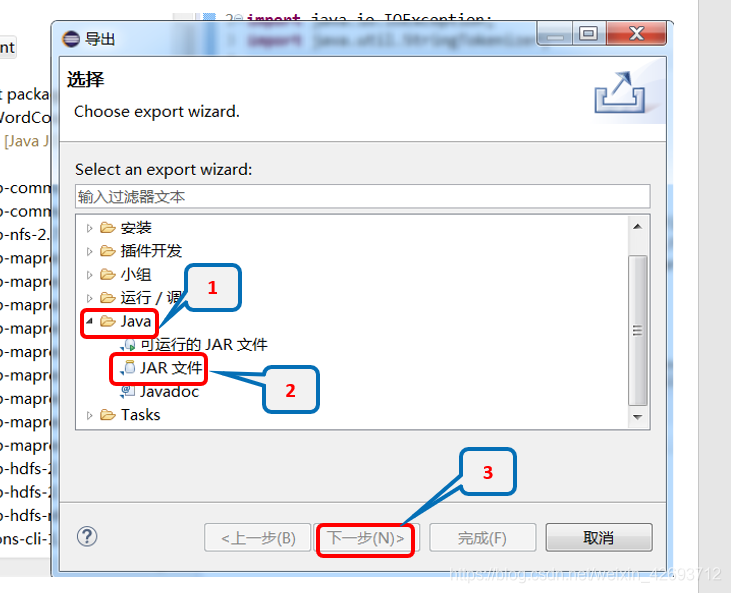
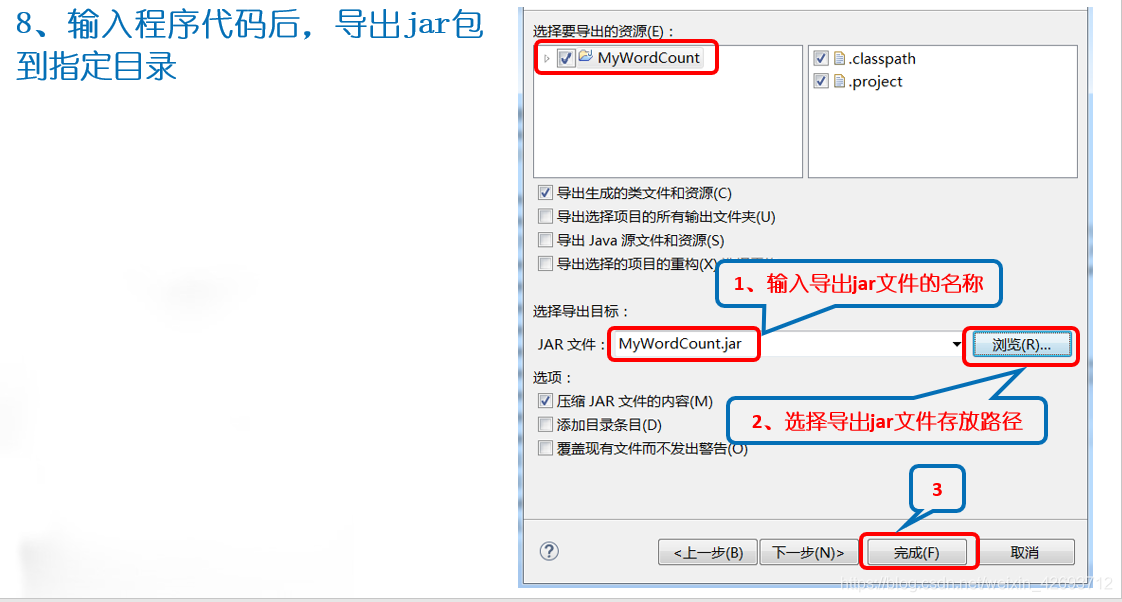
将导出的jar包放到hadoop目录用户下
(在/home/gaoyu(建立的什么就是什么,可能是hadoop)下新建wordcount文件夹,然后将jar包放进去)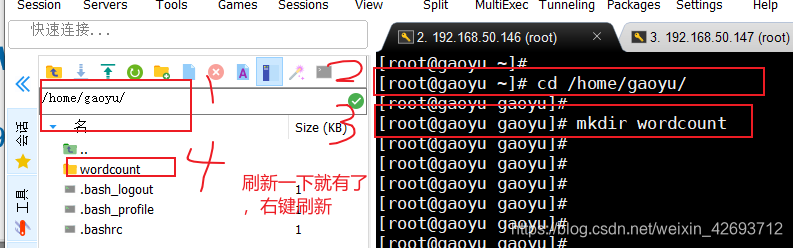
拖进去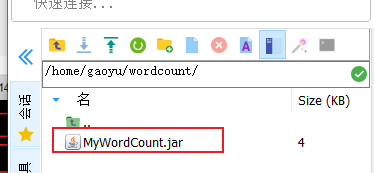
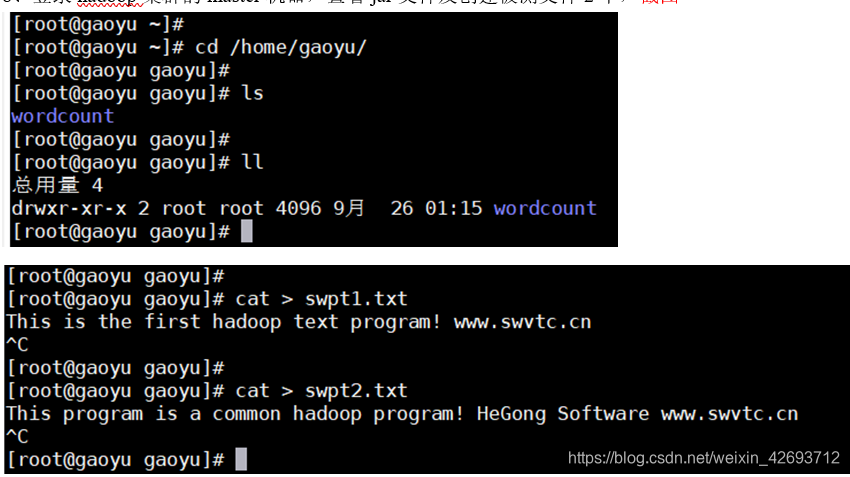
登录hadoop集群的主机,进入刚才的gaoyu目录下,创建两个txt文件,创建txt文件的时候一定要先回车,在按ctrl+c才能保存
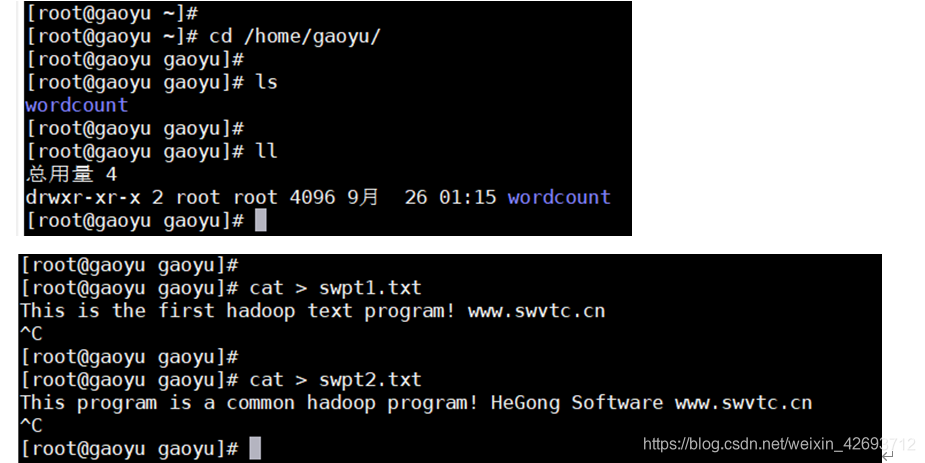
将这两个文件移动到wordcount目录下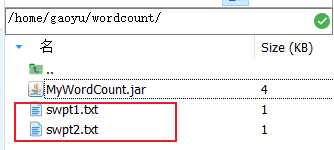
并且修改所有属主和属组为gaoyu(有的是hadoop)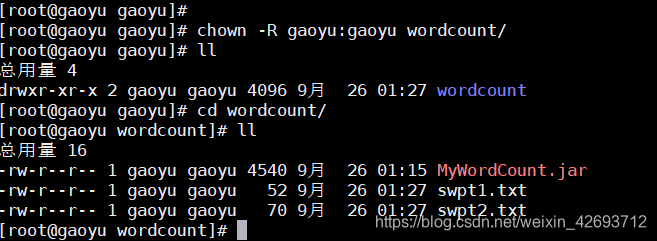
切换回gaoyu(hadoop)目录,创建input目录,如果存在则不用创建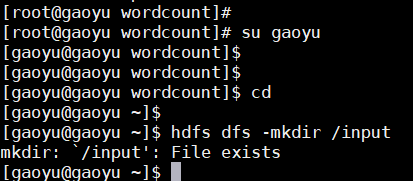
切回root su root
上传新建的两个文件swpt1和2到input文件下,并查看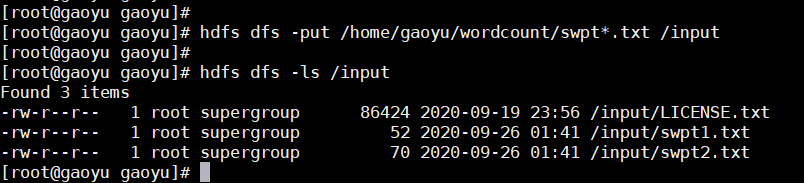
删除output目录,以及input目录下其他文件hdfs dfs -rmr /output
hdfs dfs -rm /input/LICENSE.txt
删除成功
3.运行MyWordCount
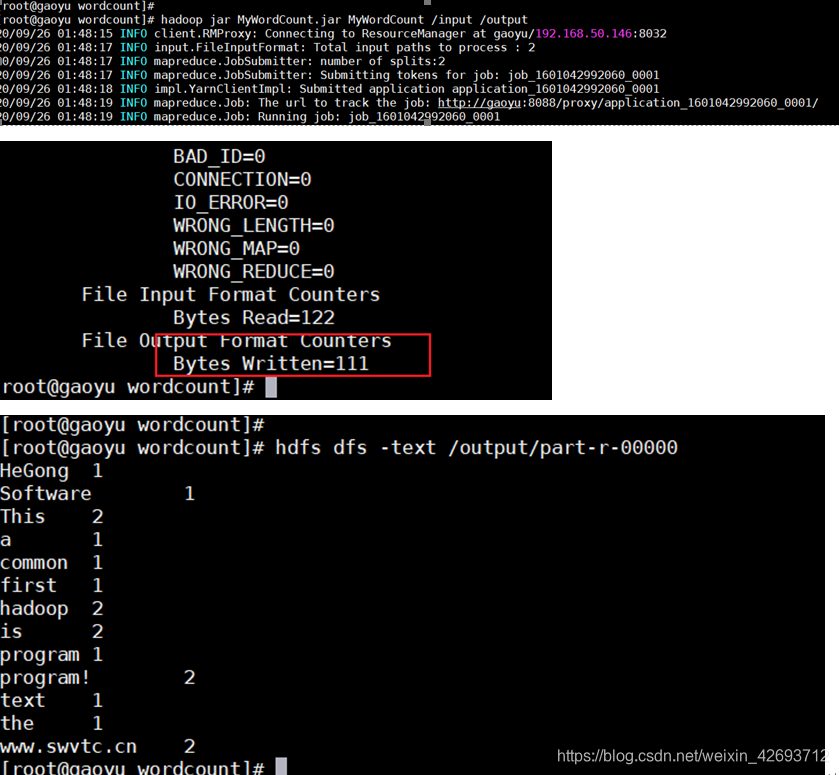
查看网页结果